
After much anticipation, Xiaohongshu’s translation feature finally arrived on the third weekend of January 2025! Here are some tips and things to know👇🏻:
– Upgrade Xiaohongshu (Red Note) to the latest version.
– Try changing your language settings, including Xiaohongshu and phone system settings.
– Currently supports single-language translation only; mixed languages or emojis won’t trigger it.
– If it still doesn’t work, some users suggest the “kill-it” trick: post a comment in English, exit the app, then reopen Xiaohongshu to activate the translation feature
Xiaohongshu’s developers are incredibly fast, with users saying they’ve never seen updates this quick. Is this the legendary “China speed”?

Everyone worldwide is thrilled, except for translator softwares lol. Despite launching in just a week, the translation performs excellently, making cross-border browsing a breeze. Chinese internet slang like “u1s1,” “yyds,” and “cpdd” are accurately understood and annotated.
- u1s1 – To be honest
- yyds – Forever the best, Immortal
- cpdd – Couple search, Looking for a couple
Our colleague admitted she didn’t know what “cpdd” meant—proof that humans are no match for GPT. Xiaohongshu, are you creating a translation tool or a meme encyclopedia? An added bonus is that Chinese dialects are also being translated.
Even if there are errors in the original text, it won’t affect the translation. Xiaohongshu thoughtfully annotates them.

Xiaohongshu, you’re really considering teaching languages for me, I’m touched.
Clearly, the new translation feature on Xiaohongshu is backed by a 대형 언어 모델, and users are eager to test the model behind it. For example, they start with a simple translation, then write a few lines of poetry.

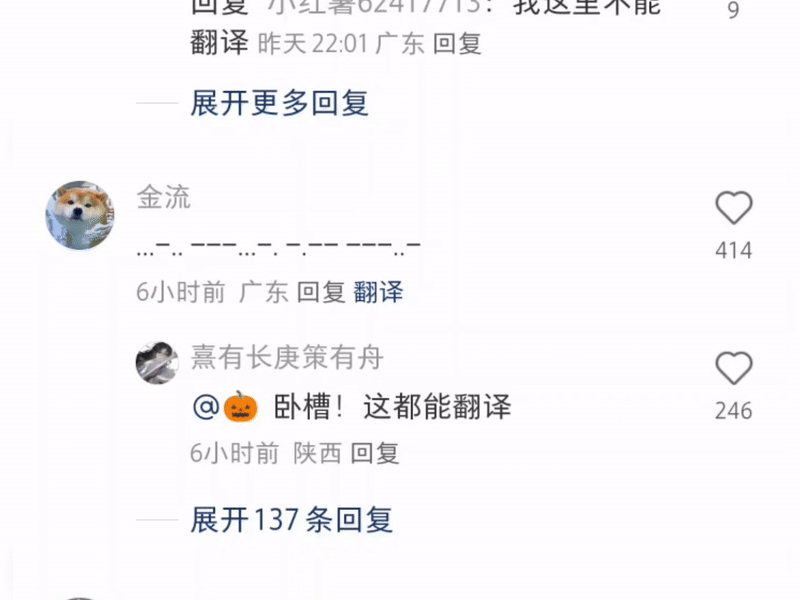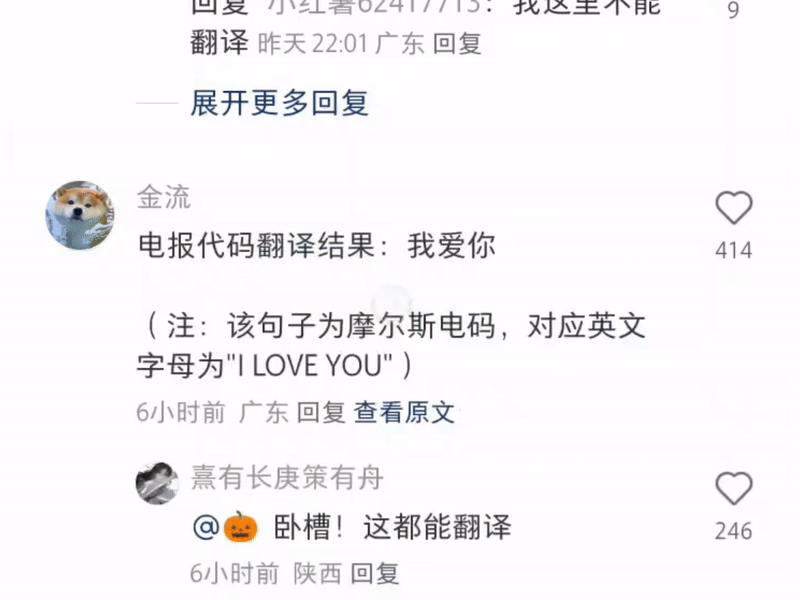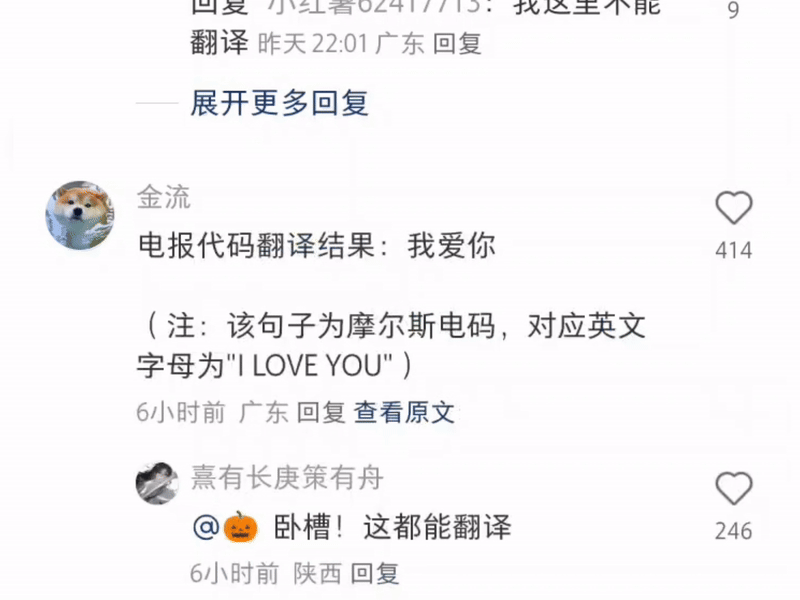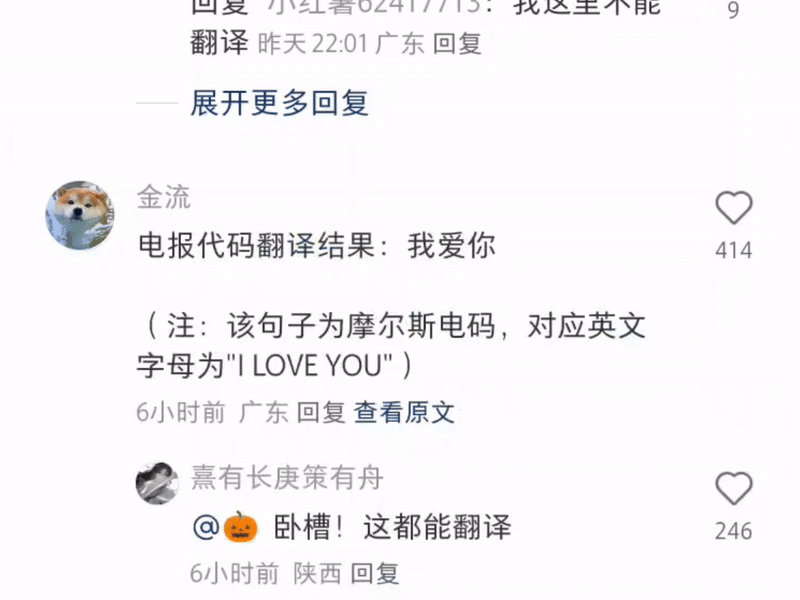
Some even type a string of Morse code for it to translate—this is Xiaohongshu, not a spy thriller!
Unilaterally declaring: Xiaohongshu is now the most powerful multifunctional translation software.
Handling translation tasks with a large language model is already quite effective, but on a content-rich social platform like Xiaohongshu, there are still many challenges.
The diversity of language is the most challenging. Some culturally specific terms, idiomatic expressions, or metaphors, like idioms and slang, are difficult to translate accurately.
There are also names and nicknames that the model might not distinguish well between what needs translation and what should remain unchanged.
For instance, “orange man” was directly translated to “橙人,” but it actually refers to Trump.

Beyond accuracy, ordinary users might not perceive the computational resources required for translation.
On a platform as content-rich as Xiaohongshu, users might post just a few letters or notes as long as several hundred words. In comparison, translating longer content consumes more resources and increases system load.
Additionally, with users from various countries, the wide distribution of time zones means the system rarely experiences low load times.
When both sides are awake, the brief overlap in time zones can lead to a sudden surge in translation requests, requiring the system to handle a large number of concurrent requests in a short time, which is a significant test of its concurrent processing capabilities.
Xiaohongshu is way too cool
There is no accurate information yet on which model the new translation feature uses. Under some users’ “interrogation,” it seems to be GPT. Some users “interrogated” and found it to be Zhipu.

Considering the cost issue, it’s hard to say for sure. GPT has a large number of parameters and high computational costs, making it unsuitable for deployment in resource-constrained environments.
A more feasible option might be to choose a student model and use GPT as a teacher model for distillation. Student models typically have fewer parameters and faster inference speeds, while trying to retain the capabilities of the teacher model.
At the same time, this approach might be more promising for Xiaohongshu.
Xiaohongshu has long been exploring AI technologies like large language models and multimodal systems, but has always focused on algorithm optimization. They have previously developed some small AI features.
Few people know that at the 2024 AAAI conference, Xiaohongshu’s search algorithm team proposed a new idea for model distillation.

The Xiaohongshu search algorithm team introduced an innovative framework that fully utilizes negative sample knowledge during the distillation of large model inference capabilities.
“Negative samples” is an interesting concept. Traditional distillation generally focuses only on positive samples, which is understandable: teachers teach students the correct way to solve problems, ensuring they understand and imitate.
However, during school, you probably also kept a “mistake book,” recording errors and areas where your understanding was weak. These mistakes are “negative samples”. In Xiaohongshu’s comment section, inaccurate translations are negative samples.
Just like “mistakes” contain important information, negative samples can help student models identify incorrect predictions, enhance their discrimination ability, improve handling of difficult samples, and maintain consistency in complex language expressions.
For instance, if you want to discuss financial terms with international friends in the comment section, the word “bank” might frequently appear. It also has other meanings: “riverbank,” and it can also be used as a verb.
Through negative sample learning, the model is trained to recognize polysemous expressions, correct translation logic, and generate more natural content.
The advantage of negative samples also extends to supporting less common languages. It’s important to note that this isn’t just for American users; users from all over the world are joining in: Serbia, Peru, and some indigenous regions of Australia.

By utilizing negative samples (including common translation error patterns), student models can identify and avoid frequent errors, enhancing translation capabilities for low-resource languages.
The framework proposed by the Xiaohongshu team is an innovative application of distillation, initially aimed at extracting complex reasoning capabilities from large language models and transferring them to specialized small models. At the time, it wasn’t clear what specific tasks could be accomplished, and translation didn’t seem to be the focus.
Perhaps no one knew that this framework would, a year later, help Xiaohongshu become a bridge for international communication.
As the saying goes: opportunity always favors the prepared.
출처 이판르
면책 조항: 위에 제시된 정보는 Cooig.com과 독립적으로 ifanr.com에서 제공합니다. Cooig.com은 판매자와 제품의 품질과 신뢰성에 대해 어떠한 진술과 보증도 하지 않습니다. Cooig.com은 콘텐츠의 저작권과 관련된 위반에 대한 모든 책임을 명시적으로 부인합니다.



